
iOS 性能监控(2)——卡顿
前文探讨了 iOS 中进行线上监控 CPU、Memory、FPS 等指标的原理以及具体实现方法。本文则继续探讨如何在 iOS 中进行线上监控卡顿的原理及实现。
卡顿
相关系统原理
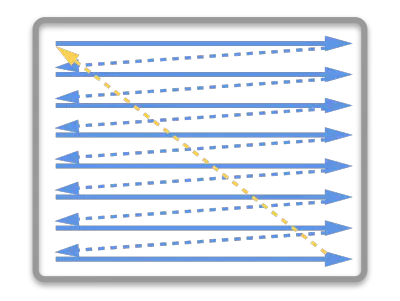
那么为什么会出现卡顿呢?为了解释这个问题首先需要了解一下屏幕图像的显示原理。首先从 CRT 显示器原理说起,如下图所示。CRT 的电子枪从上到下逐行扫描,扫描完成后显示器就呈现一帧画面。然后电子枪回到初始位置进行下一次扫描。为了同步显示器的显示过程和系统的视频控制器,显示器会用硬件时钟产生一系列的定时信号。当电子枪换行进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync ;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync 。显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏了,但其原理基本一致。
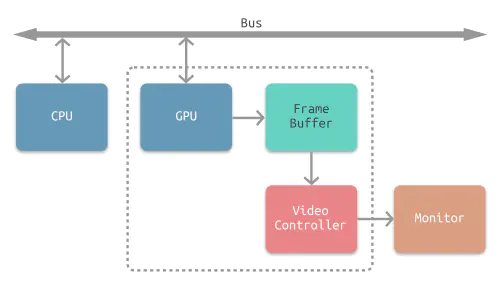
下图所示为常见的 CPU、GPU、显示器工作方式。CPU 计算好显示内容(如:视图的创建、布局计算、图片解码、文本绘制)提交至 GPU,GPU 渲染完成后将渲染结果存入帧缓冲区,视频控制器会按照 VSync 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。
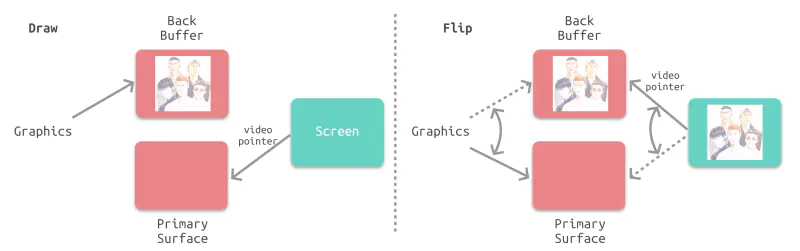
最简单的情况下,帧缓冲区只有一个。此时,帧缓冲区的读取和刷新都都会有比较大的效率问题。为了解决效率问题,GPU 通常会引入两个缓冲区,即 双缓冲机制 。事实上,iPhone 使用的就是双缓冲机制。在这种情况下,GPU 会预先渲染一帧放入一个缓冲区中,用于视频控制器的读取。当下一帧渲染完毕后,GPU 会直接把视频控制器的指针指向第二个缓冲器。
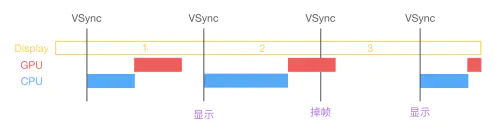
双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象,如下图:

为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是 V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。当 CPU 和 GPU 计算量比较大时,一旦它们的完成时间错过了下一次 C-Sync 的到来(通常是 1000/6=16.67ms),这样就会出现显示屏还是之前帧的内容,这就是界面卡顿的原因。
FPS 卡顿监控方案
FPS 卡顿监控方案的原理是 通过一段连续的 FPS 计算丢帧率来衡量当前页面绘制的质量 。
具体实现方式可以通过 iOS 性能监控(1)——CPU、Memory、FPS 一文中的 FPS 监控方法进行 FPS 数据采集,然后处理数据。这里不做多余的介绍。
主线程卡顿监控方案
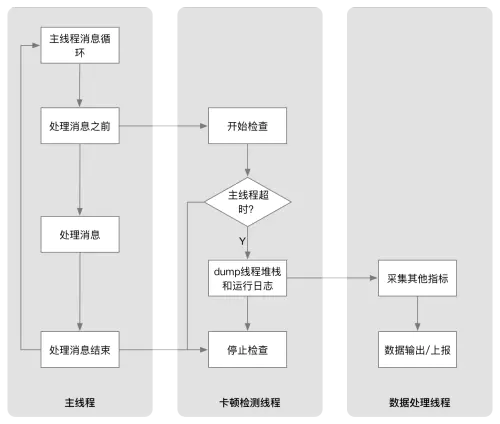
主线程卡顿监控方案的原理是 通过子线程监控主线程的 RunLoop,判断两个状态区域之间的耗时是否达到一定阈值 。因为主线程绝大部分计算或绘制任务都是以 RunLoop 为单位发生。单次 RunLoop 如果时长超过 16ms,就会导致 UI 体验的卡顿。
美团的移动端性能监控方案 Hertz 采用的就是这种方式。
首先我们需要了解一下 RunLoop 的原理。
RunLoop 定义
RunLoop 是 iOS 事件响应与任务处理最核心的机制。当有持续的异步任务需求时,我们会创建一个独立的生命周期可控的线程。 RunLoop 就是控制线程生命周期并接收事件进行处理的机制 。
RunLoop 机制
主线程(有 RunLoop 的线程)几乎所有函数都从以下六个函数之一的函数调起:
CFRUNLOOP_IS_CALLING_OUT_TO_AN_OBSERVER_CALLBACK_FUNCTION- CFRunloop is calling out to an abserver callback function
- 用于向外部报告 RunLoop 当前状态的改变,框架中很多机制都由 RunLoopObserver 触发,如:CAAnimation
CFRUNLOOP_IS_CALLING_OUT_TO_A_BLOCK- CFRunloop is calling out to a block
- 消息通知、非延迟的 perform、dispatch 调用、block 回调、KVO
CFRUNLOOP_IS_SERVICING_THE_MAIN_DISPATCH_QUEUE- CFRunloop is servicing the main dispatch queue
- 执行主队列上的任务
CFRUNLOOP_IS_CALLING_OUT_TO_A_TIMER_CALLBACK_FUNCTION- CFRunloop is calling out to a timer callback function
- 基于定时器的延迟的 perfrom,dispatch 调用
CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE0_PERFORM_FUNCTION- CFRunloop is calling out to a source 0 perform function
- 处理 App 内部事件、App自己负责管理(触发),如:
UIEvent、CFSocket。普通函数调用,系统调用
CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE1_PERFORM_FUNCTION- CFRunloop is calling out to a source 1 perform function
- 由 RunLoop 和内核管理,Mach port 驱动,如:
CFMachPort、CFMessagePort
RunLoop 运行时
如下所示为 CFRunLoop 源码中的核心方法 CFRunLoopRun 简化后的主要逻辑。
int32_t __CFRunLoopRun() {
// 1. 通知 Observers:即将进入 RunLoop
__CFRunLoopDoObservers(KCFRunLoopEntry);
do {
// 2. 通知Observers:即将要处理 timer
__CFRunLoopDoObservers(kCFRunLoopBeforeTimers);
// 3. 通知Observers:即将要处理 source
__CFRunLoopDoObservers(kCFRunLoopBeforeSources);
// 处理非延迟的主线程调用
__CFRunLoopDoBlocks();
// 处理 UIEvent 事件
__CFRunLoopDoSource0();
// GCD dispatch main queue
CheckIfExistMessagesInMainDispatchQueue();
// 4. 通知 Observers:即将进入休眠等待
__CFRunLoopDoObservers(kCFRunLoopBeforeWaiting);
// 等待内核mach_msg事件
mach_port_t wakeUpPort = SleepAndWaitForWakingUpPorts();
// mach_msg_trap
// 休眠中 Zzz...
// Received mach_msg, wake up
// 5. 通知 Observers:从休眠等待中醒来
__CFRunLoopDoObservers(kCFRunLoopAfterWaiting);
if (wakeUpPort == timerPort) {
// 处理因timer的唤醒
__CFRunLoopDoTimers();
} else if (wakeUpPort == mainDispatchQueuePort) {
// 处理异步方法唤醒,如:dispatch_async
__CFRUNLOOP_IS_SERVICING_THE_MAIN_DISPATCH_QUEUE__ ()
} else {
// UI 刷新,动画显示
__CFRunLoopDoSource1();
}
// 再次确保是否有同步的方法需要调用
__CFRunLoopDoBlocks()
} while(!stop && !timeout);
// 6. 通知 Observers:即将退出runloop
__CFRunLoopDoObservers(CFRunLoopExit);
}
RunLoop 在运行时一直在向外部报告当前状态的更新,其状态定义如下:
typedef CF_OPTIONS(CFOptionFlags, CFRunLoopActivity) {
kCFRunLoopEntry , // 进入 loop
kCFRunLoopBeforeTimers , // 触发 Timer 回调
kCFRunLoopBeforeSources , // 触发 Source0 回调
kCFRunLoopBeforeWaiting , // 等待 mach_port 消息
kCFRunLoopAfterWaiting , // 接收 mach_port 消息
kCFRunLoopExit , // 退出 loop
kCFRunLoopAllActivities // loop 所有状态改变
}
从 RunLoop 运行逻辑中,不难发现 NSRunLoop 调用方法主要在于两个状态区间:
kCFRunLoopBeforeSources和kCFRunLoopBeforeWaiting之间kCFRunLoopAfterWaiting之后
如果这两个时间内耗时太久而无法进入下一步,可以线程受阻。如果这个线程时主线程,表现出来就是出现了卡顿。
代码实现
我们可以通过 CFRunLoopObserverRef 实时获取 NSRunLoop 的状态。具体使用方法如下:
首先创建一个 CFRunLoopObserverContext 观察者 observer。然后将观察者 observer 添加到主线程 RunLoop 的 kCFRunLoopCommonModes 模式下进行观察。
- (void)registerObserver {
CFRunLoopObserverContext context = {0,(__bridge void*)self,NULL,NULL};
CFRunLoopObserverRef observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runLoopObserverCallBack,
&context);
CFRunLoopAddObserver(CFRunLoopGetMain(), observer, kCFRunLoopCommonModes);
}
static void runLoopObserverCallBack(CFRunLoopObserverRef observer, CFRunLoopActivity activity, void *info) {
MyClass *object = (__bridge MyClass*)info;
object->activity = activity;
}
然后,创建一个持续的子线程专门用来监控主线程的 RunLoop 状态。为了让计算更精确,需要让子线程更及时的获知主线程 RunLoop 状态变化,dispatch_semaphore_t 是一个不错的选择。另外,卡顿需要覆盖多次连续短时间卡顿和单次长时间卡顿两种情景,所以判定条件也需要做适当优化。优化后的代码实现如下所示:
- (void)registerObserver {
CFRunLoopObserverContext context = {0,(__bridge void*)self,NULL,NULL};
CFRunLoopObserverRef observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runLoopObserverCallBack,
&context);
CFRunLoopAddObserver(CFRunLoopGetMain(), observer, kCFRunLoopCommonModes);
// 创建信号
semaphore = dispatch_semaphore_create(0);
// 在子线程监控时长
dispatch_async(dispatch_get_global_queue(0, 0), ^{
while (YES) {
// 假定连续5次超时50ms认为卡顿(当然也包含了单次超时250ms)
long st = dispatch_semaphore_wait(semaphore, dispatch_time(DISPATCH_TIME_NOW, 50*NSEC_PER_MSEC));
if (st != 0) {
if (activity == kCFRunLoopBeforeSources || activity==kCFRunLoopAfterWaiting) {
if (++timeoutCount < 5)
continue;
NSLog(@"好像有点儿卡哦");
}
}
timeoutCount = 0;
}
});
}
static void runLoopObserverCallBack(CFRunLoopObserverRef observer, CFRunLoopActivity activity, void *info) {
MyClass *object = (__bridge MyClass*)info;
// 记录状态值
object->activity = activity;
// 发送信号
dispatch_semaphore_t semaphore = moniotr->semaphore;
dispatch_semaphore_signal(semaphore);
}
检测到卡顿时应该立刻获取卡顿的方法堆栈信息,并推送至服务端共开发者分析,从而解决卡顿问题。
获取堆栈信息的一种方法是: 直接调用系统函数 。这种方法的优点是 性能消耗小 。缺点是 它只能够获取简单的信息,无法配合 dSYM 来获取具体是哪行代码出了问题,而且能够获取的信息类型也有限 。
直接调用系统函数的主要思路是:用 signal 进行错误信息获取。具体代码如下:
static int s_fatal_signals[] = {
SIGABRT,
SIGBUS,
SIGFPE,
SIGILL,
SIGSEGV,
SIGTRAP,
SIGTERM,
SIGKILL,
};
static int s_fatal_signal_num = sizeof(s_fatal_signals) / sizeof(s_fatal_signals[0]);
void UncaughtExceptionHandler(NSException *exception) {
NSArray *exceptionArray = [exception callStackSymbols]; // 得到当前调用栈信息
NSString *exceptionReason = [exception reason]; // 非常重要,就是崩溃的原因
NSString *exceptionName = [exception name]; // 异常类型
}
void SignalHandler(int code) {
NSLog(@"signal handler = %d",code);
}
void InitCrashReport() {
// 系统错误信号捕获
for (int i = 0; i < s_fatal_signal_num; ++i) {
signal(s_fatal_signals[i], SignalHandler);
}
//oc 未捕获异常的捕获
NSSetUncaughtExceptionHandler(&UncaughtExceptionHandler);
}
int main(int argc, char * argv[]) {
@autoreleasepool {
InitCrashReport();
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
获取堆栈信息的另一种方法是: 直接使用 PLCrashReporter 第三方开源库 。这种方法的优点是 能够定位到问题代码的具体位置,而且性能消耗也不大 。具体代码如下:
PLCrashReporterConfig *config = [[PLCrashReporterConfig alloc] initWithSignalHandlerType:PLCrashReporterSignalHandlerTypeBSD
symbolicationStrategy:PLCrashReporterSymbolicationStrategyAll];
PLCrashReporter *reporter = [[PLCrashReporter alloc] initWithConfiguration:config];
// 获取数据
NSData *lagData = [reporter generateLiveReport];
// 转换成 PLCrashReport 对象
PLCrashReport *lagReport = [[PLCrashReport alloc] initWithData:lagData error:NULL];
// 进行字符串格式化处理
NSString *lagReportString = [PLCrashReportTextFormatter stringValueForCrashReport:lagReport withTextFormat:PLCrashReportTextFormatiOS];
// 将字符串上传服务器
NSLog(@"lag happen, detail below: \n %@",lagReportString);




